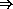 #f
#f(atom? '(3 . 4))
#f(atom? '())
#t(atom? 3)
#t

This chapter describes operations specific to Chez Scheme on nonnumeric objects, including standard objects such as pairs and numbers and Chez Scheme extensions such as boxes and records. Chapter 7 describes operations on numbers. See Chapter 6 of The Scheme Programming Language, Second Edition or the Revised5 Report on Scheme for a description of standard operations on objects.
procedure: (atom? obj)
returns: #t if obj is not a pair, #f otherwise
atom? is equivalent to (lambda (x) (not (pair? x))).
(atom? '(a b c)) #f
(atom? '(3 . 4)) #f
(atom? '()) #t
(atom? 3) #t
procedure: (last-pair list)
returns: the last pair of a list
list must not be empty. last-pair returns the last pair (not the last element) of list. list may be an improper list, in which case the last pair is the pair containing the last element and the terminating object.
(last-pair '(a b c d)) (d)
(last-pair '(a b c . d)) (c . d)
procedure: (list-copy list)
returns: a copy of list
list-copy returns a list equal? to list, using new pairs to reform the top-level list structure.
(list-copy '(a b c)) (a b c)
(let ([ls '(a b c)])
(equal? ls (list-copy ls))) #t
(let ([ls '(a b c)])
(let ([ls-copy (list-copy ls)])
(or (eq? ls-copy ls)
(eq? (cdr ls-copy) (cdr ls))
(eq? (cddr ls-copy) (cddr ls))))) #f
procedure: (list* obj ... final-obj)
returns: a list of obj ... terminated by final-obj
If the objects obj ... are omitted, the result is simply final-obj. Otherwise, a list of obj ... is constructed, as with list, except that the final cdr field is final-obj instead of (). If final-obj is not a list, the result is an improper list.
(list* '()) ()
(list* '(a b)) (a b)
(list* 'a 'b 'c) (a b . c)
(list* 'a 'b '(c d)) (a b c d)
procedure: (make-list n)
procedure: (make-list n obj)
returns: a list of n objs
n must be a nonnegative integer. If obj is omitted, the elements of the list are unspecified.
(make-list 0 '()) ()
(make-list 3 0) (0 0 0)
(make-list 2 "hi") ("hi" "hi")
procedure: (sort predicate list)
procedure: (sort! predicate list)
returns: a list containing the elements of list sorted according to predicate
predicate should be a procedure that expects two arguments and returns #t if its first argument must precede its second in the sorted list. That is, if predicate is applied to two elements x and y, where x appears after y in the input list, it should return true only if x should appear before y in the output list. If this constraint is met, sort and sort! perform stable sorts, i.e., two elements are reordered only when necessary according to predicate. Duplicate elements are not removed.
sort! performs the sort destructively, using pairs from the input list to form the output list.
(sort < '(3 4 2 1 2 5)) (1 2 2 3 4 5)
(sort > '(0.5 1/2)) (0.5 1/2)
(sort > '(1/2 0.5)) (1/2 0.5))
(list->string
(sort char>?
(string->list "hello"))) "ollhe"
procedure: (merge predicate list1 list2)
procedure: (merge! predicate list1 list2)
returns: list1 merged with list2 in the order specified by predicate
predicate should be a procedure that expects two arguments and returns #t if its first argument must precede its second in the merged list. That is, if predicate is applied to two objects x and y, where x is taken from the second list and y is taken from the first list, it should return true only if x should appear before y in the output list. If this constraint is met, merge and merge! are stable, in that items from list1 are placed in front of equivalent items from list2 in the output list. Duplicate elements are included in the merged list.
merge! combines the lists destructively, using pairs from the input lists to form the output list.
(merge char<?
'(#\a #\c)
'(#\b #\c #\d)) (#\a #\b #\c #\c #\d)
(merge <
'(1/2 2/3 3/4)
'(0.5 0.6 0.7)) (1/2 0.5 0.6 2/3 0.7 3/4)
procedure: (remq obj list)
procedure: (remv obj list)
procedure: (remove obj list)
procedure: (remq! obj list)
procedure: (remv! obj list)
procedure: (remove! obj list)
returns: a list containing the elements of list with all occurrences of obj removed
These procedures traverse the argument list, removing any objects that are equivalent to obj. The elements remaining in the output list are in the same order as they appear in the input list.
The equivalence test for remq and remq! is eq?, for remv and remv! is eqv?, and for remove and remove! is equal?.
remq!, remv! and remove! use pairs from the input list to build the output list. They perform less allocation but are not necessarily faster than their nondestructive counterparts. Their use can easily lead to confusing or incorrect results if used indiscriminately.
(remq 'a '(a b a c a d)) (b c d)
(remq 'a '(b c d)) (b c d)
(remq! 'a '(a b a c a d)) (b c d)
(remv 1/2 '(1.2 1/2 0.5 3/2 4)) (1.2 0.5 3/2 4)
(remv! #\a '(#\a #\b #\c)) (#\b #\c)
(remove '(b) '((a) (b) (c))) ((a) (c))
(remove! '(c) '((a) (b) (c))) ((a) (b))
procedure: (substq new old tree)
procedure: (substv new old tree)
procedure: (subst new old tree)
procedure: (substq! new old tree)
procedure: (substv! new old tree)
procedure: (subst! new old tree)
returns: a tree with new substituted for occurrences of old in tree
These procedures traverse tree, replacing all objects equivalent to the object old with the object new.
The equivalence test for substq and substq! is eq?, for substv and substv! is eqv?, and for subst and subst! is equal?.
substq!, substv!, and subst! perform the substitutions destructively. They perform less allocation but are not necessarily faster than their nondestructive counterparts. Their use can easily lead to confusing or incorrect results if used indiscriminately.
(substq 'a 'b '((b c) b a)) ((a c) a a)
(substv 2 1 '((1 . 2) (1 . 4) . 1)) ((2 . 2) (2 . 4) . 2)
(subst 'a
'(a . b)
'((a . b) (c a . b) . c)) (a (c . a) . c)
(let ([tr '((b c) b a)])
(substq! 'a 'b tr)
tr) ((a c) a a)
procedure: (reverse! list)
returns: a list containing the elements of list in reverse order
reverse! destructively reverses list by reversing its links. Using reverse! in place of reverse reduces allocation but is not necessarily faster than reverse. Its use can easily lead to confusing or incorrect results if used indiscriminately.
(reverse! '()) ()
(reverse! '(a b c)) (c b a)
(let ([x '(a b c)])
(reverse! x)
x) (a)
(let ([x '(a b c)])
(set! x (reverse! x))
x) (c b a)
procedure: (append! list ...)
returns: the concatenation of the input lists
Like append, append! returns a new list consisting of the elements of the first list followed by the elements of the second list, the elements of the third list, and so on. Unlike append, append! reuses the pairs in all of the arguments in forming the new list. That is, the last cdr of each list argument but the last is changed to point to the next list argument. If any argument but the last is the empty list, it is essentially ignored. The final argument (which need not be a list) is not altered.
append! performs less allocation than append but is not necessarily faster. Its use can easily lead to confusing or incorrect results if used indiscriminately.
(append! '(a b) '(c d)) (a b c d)
(let ([x '(a b)])
(append! x '(c d))
x) (a b c d)
procedure: (substring-fill! string start end char)
returns: unspecified
The characters of string from start (inclusive) to end
(exclusive) are set to char.
start and end must be nonnegative integers; start
must be strictly less than the length of string, while end may
be less than or equal to the length of string.
If 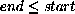 , the string is left unchanged.
, the string is left unchanged.
(let ([str (string-copy "a tpyo typo")])
(substring-fill! str 2 6 #\X)
str) "a XXXX typo"
procedure: (char- char1 char2)
returns: the integer difference between char1 and char2
char- subtracts the integer value of char2 from the integer value of char1 and returns the difference. The following examples assume that the integer representation is the ASCII code for the character.
(char- #\f #\e) 1
(define digit-value
; returns the digit value of the base-r digit c, or #f if c
; is not a valid digit
(lambda (c r)
(let ([v (cond
[(char<=? #\0 c #\9) (char- c #\0)]
[(char<=? #\A c #\Z) (char- c #\7)]
[(char<=? #\a c #\z) (char- c #\W)]
[else 36])])
(and (fx< v r) v))))
(digit-value #\8 10) 8
(digit-value #\z 10) #f
(digit-value #\z 36) 35
char- might be defined as follows.
(define char-
(lambda (c1 c2)
(- (char->integer c1) (char->integer c2))))
procedure: (vector-copy vector)
returns: a copy of vector
vector-copy creates a new vector of the same length and contents as vector. The elements themselves are not copied.
(vector-copy '#(a b c)) #(a b c)
(let ([v '#(a b c)])
(eq? v (vector-copy v))) #f
Boxes are single-cell objects that are primarily useful for providing an "extra level of indirection." This extra level of indirection is typically used to allow more than one body of code or data structure to share a reference, or pointer, to an object. For example, boxes may be used to implement call-by-reference semantics in an interpreter for a language employing this parameter passing discipline.
Boxes are written with the prefix #& (pronounced "hash-ampersand"). For example, #&(a b c) is a box holding the list (a b c).
procedure: (box? obj)
returns: #t if obj is a box, #f otherwise
(box? '#&a) #t
(box? 'a) #f
(box? (box 3)) #t
procedure: (box obj)
returns: a new box containing obj
(box 'a) #&a
(box (box '(a b c))) #&#&(a b c)
procedure: (unbox box)
returns: contents of box
(unbox #&a) a
(unbox #&#&(a b c)) #&(a b c)
(let ([b (box "hi")])
(unbox b)) "hi"
procedure: (set-box! box obj)
returns: unspecified
set-box! sets the contents of box to obj.
(let ([b (box 'x)])
(set-box! b 'y)
b) #&y
(let ([incr!
(lambda (x)
(set-box! x (+ (unbox x) 1)))])
(let ([b (box 3)])
(incr! b)
(unbox b))) 4
procedure: (string->uninterned-symbol string)
returns: a new, unique symbol whose name is string
Each call to string->uninterned-symbol returns a new symbol, distinct from all others in the system, regardless of similarity in name. As with string->symbol, no case conversion is performed. The name uninterned symbol comes from the fact that these symbols are not registered, or "interned," in the system's "oblist" (page 92). Uninterned symbols are useful, for example, as lexical identifier names in program transformation systems or program improvers. See also the procedure gensym.
Uninterned symbols print with a #: prefix by default. This prefix may be suppressed by setting the parameter print-gensym to false.
(string->uninterned-symbol "g") #:g
(string->uninterned-symbol "G") #:|G|
(eq? (string->uninterned-symbol "g") 'g) #f
(eq? (string->uninterned-symbol "g")
(string->uninterned-symbol "g")) #f
procedure: (gensym)
returns: a new uninterned symbol
gensym returns a new uninterned symbol with a different name each time it is applied. The name is formed by combining an internal prefix with the current value of an internal counter. After each name is formed, the internal counter is incremented.
gensym produces symbols with different names not because this makes the symbol unique (which is ensured just by creating an uninterned symbol), but because it is much easier to debug a program that employs generated symbols if each distinct generated symbol looks distinct as well.
The following examples assume that the gensym prefix is "g" and the internal count is set (initially) to zero.
See the note about printing of uninterned symbols in the description of string->uninterned-symbol above.
(gensym) #:g0
(gensym) #:g1
(eq? (gensym) (gensym)) #f
parameter: gensym-prefix
parameter: gensym-count
The parameters gensym-prefix and gensym-count are used to access and set the internal prefix and counter from which gensym forms the names of the symbols it generates. gensym-prefix defaults to the string "g" and may be set to any object. gensym-count defaults to 0 and may be set to any nonnegative integer.
(parameterize ([gensym-prefix "genny"]
[gensym-count 17])
(let ([g1 (gensym)])
(list g1 (gensym)))) (#:genny17 #:genny18)
Chez Scheme delays the creation of a gensym's name until the symbol is actually printed whenever the default prefix is used. This can lead to substantial savings in programs that create many gensyms that are never printed.
procedure: (uninterned-symbol? obj)
returns: #t if obj is an uninterned symbol, #f otherwise
(uninterned-symbol? (string->symbol "z")) #f
(uninterned-symbol? (string->uninterned-symbol "z")) #t
(uninterned-symbol? 'a) #f
(uninterned-symbol? '#:a) #t
(uninterned-symbol? (gensym)) #t
(uninterned-symbol? '(a b c)) #f
procedure: (putprop symbol key value)
returns: unspecified
Chez Scheme associates a property list with each symbol, allowing multiple key-value pairs to be stored directly with the symbol. New key-value pairs may be placed in the property list or retrieved in a manner analogous to the use of association lists, using the procedures putprop and getprop. Property lists are often used to store information related to the symbol itself. For example, a natural language program might use symbols to represent words, using their property lists to store information about use and meaning.
putprop associates value with key on the property list of symbol. key and value may be any types of object, although key is typically a symbol.
putprop may be used to establish a new property or to change an existing property.
See the examples under getprop below.
procedure: (getprop symbol key)
procedure: (getprop symbol key default)
returns: the value associated with key on the property list of symbol
getprop searches the property list of symbol for a key identical to key (in the sense of eq?), and returns the value associated with this key, if any. If no value is associated with key on the property list of symbol, getprop returns default, or #f if the default argument is not supplied.
(putprop 'fred 'species 'snurd)
(putprop 'fred 'age 4)
(putprop 'fred 'colors '(black white))
(getprop 'fred 'species) snurd
(getprop 'fred 'colors) (black white)
(getprop 'fred 'nonkey) #f
(getprop 'fred 'nonkey 'unknown) unknown
(putprop 'fred 'species #f)
(getprop 'fred 'species 'unknown) #f
procedure: (remprop symbol key)
returns: unspecified
remprop removes the property with key key from the property list of symbol, if such a property exists.
(putprop 'fred 'species 'snurd)
(getprop 'fred 'species) snurd
(remprop 'fred 'species)
(getprop 'fred 'species 'unknown) unknown
procedure: (property-list symbol)
returns: a copy of the internal property list for symbol
A property list is a list of alternating keys and values, i.e., (key value ...).
(putprop 'fred 'species 'snurd)
(putprop 'fred 'colors '(black white))
(property-list 'fred) (colors (black white) species snurd)
procedure: (oblist)
returns: a list of interned symbols
The system maintains an internal symbol table used by string->symbol to insure that any two occurrences of the same identifier name resolve to the same symbol object. The oblist procedure returns a list of the symbols currently in this symbol table.
The list of interned symbols grows when a new symbol is introduced into the system. It may also shrink when the garbage collector determines that it is safe to discard a symbol. It is safe to discard a symbol only if the symbol is not accessible except through the oblist, has no top-level binding, and has no properties on its property list.
(if (memq 'tiger (oblist)) 'yes 'no) yes
(equal? (oblist) (oblist)) #t
(= (length (oblist)) (length (oblist))) #t or #f
The first example above follows from the property that all interned symbols are in the oblist from the time they are read, which happens prior to evaluation. The second example follows from the fact that no symbols can be removed from the oblist while references to those symbols exist, in this case, within the list returned by the first call to oblist (whichever call is performed first). The expression in the third example can return #f only if a garbage collection occurs sometime between the two calls to oblist, and only if one or more symbols are removed from the oblist by that collection.
Many Scheme operations return an unspecified result. Chez Scheme typically returns a special void object when the value returned by an operation is unspecified. The Chez Scheme void object is not meant to be used as a datum, and consequently does not have a reader syntax. As for other objects without a reader syntax, such as procedures and ports, Chez Scheme output procedures print the void object using a nonreadable representation, i.e., #<void>. Since the void object should be returned only by operations that do not have "interesting" values, the default waiter printer (see waiter-write) suppresses the printing of the void object. set!, set-car!, load, and write are examples of Chez Scheme operations that return the void object.
procedure: (void)
returns: the void object
void is a procedure of no arguments that returns the void object. It can be used to force expressions that are used for effect or whose values are otherwise unspecified to evaluate to a consistent, trivial value. Since most Chez Scheme operations that are used for effect return the void object, however, it is rarely necessary to explicitly invoke the void procedure.
Since the void object is used explicitly as an "unspecified" value, it is a bad idea to use it for any other purpose or to count on any given expression evaluating to the void object.
The default waiter printer suppresses the void object; that is, nothing is printed for expressions that evaluate to the void object.
(eq? (void) #f) #f
(eq? (void) #t) #f
(eq? (void) '()) #f
Chez Scheme supports the definition of new data types, or records, with fixed sets of named fields. Records may be defined via the define-record syntactic form or via the make-record-type procedure. The syntactic interface is the most commonly used interface. Each time a define-record expression is evaluated, a new datatype is generated. This datatype is unique, i.e., distinct from all other datatypes, whether built-in or defined by other record definitions, including other evaluations of the same define-record expression. Each record definition defines a constructor procedure for records of the new type, a type predicate that returns true only for records of the new type, an access procedure for each field, and an assignment procedure for each mutable field. define-record allows the programmer to control which fields are arguments to the generated constructor procedure and which are explicitly initialized by the constructor procedure. define-record also allows the programmer to define a print method that determines how records of the new type are printed by write and pretty-print. The representation of each field may also be specified, allowing interoperability with operating system routines and code written in languages other than Scheme.
The procedural interface is most commonly used to implement generic print methods, custom printers or pretty printers, inspectors, and interpreters that must handle define-record forms. The procedural interface is more flexible than the syntactic interface, but this flexibility may come with a corresponding loss in efficiency. Programmers should thus use the syntactic interface whenever it suffices. Each call to make-record-type, as with each evaluation of define-record, results in the creation of a new datatype. make-record-type produces a record-type descriptor representing the new datatype. Programs may generate constructors, type predicates, field accessors, and field mutators from the record-type descriptor.
A record-type descriptor may also be extracted from an instance of a record type, and the extracted descriptor may also be used to produce constructors, predicates, accessors, and mutators, with a few limitations noted in the description of record-type-descriptor below. This is a powerful feature that permits the coding of portable printers and object inspectors. Chez Scheme's inspector employs this feature to allow inspection and mutation of system- and user-defined records during debugging.
By default, a record is printed with the syntax
#[type-name field ...]
where field ... are the printed representations of the contents of the fields of the record. This syntax may be used as input to the reader as well, but only after the reader has been informed of the mapping from the given name to a particular record type, either via define-record's reader-name option or via record-reader. It is also possible to specify a print method that uses some other syntax for printing records of a particular type.
syntax: (define-record name (fld1 ...) ((fld2 init) ...) (opt ...))
returns: unspecified
A define-record form is a definition and may appear anywhere and only where other definitions may appear.
define-record defines a new record datatype containing a specified set of named fields and creates a set of procedures for creating and manipulating instances of the datatype. name must be an identifier. Each fld must be an identifier field-name, or it must take the form
(class type field-name)
where class and type are optional and field-name is an identifier. class, if present, must be the keyword immutable or the keyword mutable. If the immutable class specifier is present, the field is immutable; otherwise, the field is mutable. type, if present, must be one of the following keywords:
scheme-object
integer-32
unsigned-32
double-float
If a type is specified, the field can contain objects only of the specified type. If no type is specified, the field is of type scheme-object, meaning that it can contain any Scheme object.
The field identifiers name the fields of the record. The values of the n fields described by fld1 ... are specified by the n arguments to the generated constructor procedure. The values of the remaining fields, fld2 ..., are given by the corresponding expressions, init .... Each init is evaluated within the scope of the set of field names given by fld1 ... and each field in fld2 ... that precedes it, as if within a let* expression. Each of these field names is bound to the value of the corresponding field during initialization.
The following procedures are defined by define-record:
The constructor behaves as if defined as
(define make-name
(lambda (id1 ...)
(let* ([id2 init] ...)
body)))
where id1 ... are the names of the fields defined by fld1 ..., id2 ... are the names of the fields defined by fld2 ..., and body builds the record from the values of the identifiers id1 ... and id2 ....
The options opt ... control certain aspects of the datatype creation. These options are described below.
If no options are needed, the third subexpression, (opt ...), may be omitted. If no options and no fields other than those initialized by the arguments to the constructor procedure are needed, both the second and third subexpressions may be omitted. If options are specified, the second subexpression must be present, even if it contains no field specifiers.
(define-record marble (color quality))
(define x (make-marble 'blue 'medium))
(marble? x) #t
(pair? x) #f
(vector? x) #f
(marble-color x) blue
(marble-quality x) medium
(set-marble-quality! x 'low)
(marble-quality x) low
(define-record marble ((immutable color) (mutable quality))
(((mutable shape) (if (eq? quality 'high) 'round 'unknown))))
(marble-shape (make-marble 'blue 'high)) round
(marble-shape (make-marble 'blue 'low)) unknown
(define x (make-marble 'blue 'high))
(set-marble-quality! x 'low)
(marble-shape x) round
(set-marble-shape! x 'half-round)
(marble-shape x) half-round
Two options, reader-name and print-method, are supported.
(reader-name expr)
(print-method expr)
If the reader-name option is present, expr should evaluate to a string. The record-type descriptor of the defined record is registered, as with record-reader below, as the descriptor to use when records of the given name are encountered by the reader. Any previous mapping from the same name to a different record-type descriptor is dropped.
(define-record circle (center radius)
()
((reader-name "circle")))
(circle-radius '#["circle" (100 100) 50]) 50
If the print-method option is present, expr should evaluate to a procedure that accepts three arguments. The expression is evaluated in the same scope as the define-record expression. In particular, the field names are not visible, in contrast with the init expressions. Whenever the printer (write or pretty-print) encounters a record of the new type, the print method is called with the record r, a port p, and a procedure wr that should be used to write out the values of arbitrary Scheme objects that the print method chooses to include in the printed representation of the record, i.e., values of the record's fields.
(define-record marble (color quality) ()
((print-method
(lambda (r p wr)
(display "#<" p)
(wr (marble-quality r) p)
(display " quality " p)
(wr (marble-color r) p)
(display " marble>" p)))))
(make-marble 'blue 'medium) #<medium quality blue marble>
If no print method is supplied, a default print method is used. The default print method prints all records in a uniform syntax that includes both the name of the record as a string (the string equivalent of name) and the values of each of the fields.
(define-record marble (color quality))
(make-marble 'blue 'medium) #["marble" blue medium]
(let ()
(define-record ref () ((contents 'nothing)))
(let ((ref-lexive (make-ref)))
(set-ref-contents! ref-lexive ref-lexive)
ref-lexive)) #0=#["ref" #0#]
A print method may be called more than once during the printing of a single record to support cycle detection and graph printing (see print-graph), so print methods that perform side effects other than printing to the given port are discouraged. Whenever a print method is called more than once during the printing of a single record, in all but one call, a generic "bit sink" port is used to suppress output automatically so that only one copy of the object appears on the actual port. In order to avoid confusing the cycle detection and graph printing algorithms, a print method should always produce the same printed representation for each object. Furthermore, a print method should normally use the supplied procedure wr to print subobjects, though atomic values, such as strings or numbers, may be printed by direct calls to display or write or by other means.
(let ()
(define-record ref ()
((contents 'nothing))
((print-method
(lambda (r p wr)
(display "<" p)
(wr (ref-contents r) p)
(display ">" p)))))
(let ((ref-lexive (make-ref)))
(set-ref-contents! ref-lexive ref-lexive)
ref-lexive)) #0=<#0#>
Print methods need not be concerned with handling nonfalse values of the parameters print-level. The printer handles print-level automatically even when user-defined print procedures are used. Since records typically contain a small, fixed number of fields, it is usually possible to ignore nonfalse values of print-length as well.
(print-level 3)
(let ()
(define-record ref ()
((contents 'nothing))
((print-method
(lambda (r p wr)
(display "<" p)
(wr (ref-contents r) p)
(display ">" p)))))
(let ((ref-lexive (make-ref)))
(set-ref-contents! ref-lexive ref-lexive)
ref-lexive)) <<<<#[...]>>>>
procedure: (make-record-type type-name fields)
procedure: (make-record-type type-name fields print-method)
returns: a record-type descriptor for a new record type
make-record-type creates a new data type and returns a record-type descriptor, a value representing the new data type. The new type is disjoint from all others. type-name must be a string. The type name is typically used only for identification purposes, such as in printing records of the new type.
fields must be a list of field descriptors, each of which describes one field of instances of the new record type. A field descriptor is either a symbol or a list in the following form:
(class type field-name)
where class and type are optional. field-name must be a symbol. class, if present, must be the symbol immutable or the symbol mutable. If the immutable class-specifier is present, the field is immutable; otherwise, the field is mutable. type, if present, must be one of the following symbols:
scheme-object
integer-32
unsigned-32
double-float
If a type is specified, the field can contain objects only of the specified type. If no type is specified, the field is of type scheme-object, meaning that it can contain any Scheme object.
A print method for records of the new type may be specified as an optional third argument to make-record-type. See the discussion of print methods in the description of define-record above.
The behavior of a program that modifies the string type-name or the list fields or any of its sublists is unspecified.
The record-type descriptor may be passed as an argument to any of the procedures
to obtain procedures for creating and manipulating records of the new type.
(define marble
(make-record-type "marble"
'(color quality)
(lambda (r p wr)
(display "#<" p)
(wr (marble-quality r) p)
(display " quality " p)
(wr (marble-color r) p)
(display " marble>" p))))
(define make-marble
(record-constructor marble))
(define marble?
(record-predicate marble))
(define marble-color
(record-field-accessor marble 'color))
(define marble-quality
(record-field-accessor marble 'quality))
(define set-marble-quality!
(record-field-mutator marble 'quality))
(define x (make-marble 'blue 'high))
(marble? x) #t
(marble-quality x) high
(set-marble-quality! x 'low)
(marble-quality x) low
x #<low quality blue marble>
procedure: (record-type-descriptor? obj)
returns: #t if obj is a record-type descriptor, #f otherwise
(record-type-descriptor? (make-record-type "empty" '())) #t
(define-record marble (color quality))
(record-type-descriptor?
(record-type-descriptor
(make-marble 'blue 'high))) #t
procedure: (record-constructor rtd)
returns: a constructor for records of the type represented by rtd
rtd must be a record-type descriptor. The constructor accepts as many arguments as there are fields in the record; these arguments are the initial values of the fields in the order given when the record-type descriptor was created.
procedure: (record-predicate rtd)
returns: a type predicate for records of the type represented by rtd
rtd must be a record-type descriptor. The predicate accepts any value as an argument and returns #t if the value is a record of the type represented by rtd and #f otherwise.
procedure: (record-field-accessor rtd field-name)
returns: an accessor for field-name of the type represented by rtd
rtd must be a record-type descriptor, field-name must be a symbol, and the named field must be accessible. The accessor expects one argument, which must be a record of the type represented by rtd. It returns the contents of the specified field of the record.
procedure: (record-field-accessible? rtd field-name)
returns: #t if the specified field is accessible, otherwise #f
rtd must be a record-type descriptor and field-name must be a symbol. The compiler is free to eliminate a record field if it can prove that the field is not accessed. In making this determination, the compiler is free to ignore the possibility that an accessor might be created from a record-type descriptor obtained by calling record-type-descriptor on an instance of the record type.
procedure: (record-field-mutator rtd field-name)
returns: a mutator for field-name of the type represented by rtd
rtd must be a record-type descriptor, field-name must be a symbol, and the named field must be mutable. The mutator expects two arguments, r and obj. r must be a record of the type represented by rtd. obj must be a value that is compatible with the type declared for the specified field when the record-type descriptor was created. obj is stored in the specified field of the record.
procedure: (record-field-mutable? rtd field-name)
returns: #t if the specified field is mutable, otherwise #f
rtd must be a record-type descriptor and field-name must be a symbol. Any field declared immutable is immutable. In addition, the compiler is free to treat a field as immutable if it can prove that the field is never assigned. In making this determination, the compiler is free to ignore the possibility that a mutator might be created from a record-type descriptor obtained by calling record-type-descriptor on an instance of the record type.
procedure: (record-type-name rtd)
returns: the type name of the type represented by rtd
rtd must be a record-type descriptor.
(record-type-name (make-record-type "empty" '())) "empty"
procedure: (record-type-field-names rtd)
returns: a list of field names of the type represented by rtd
rtd must be a record-type descriptor. The field names are symbols.
(define-record triple ((immutable x1) (mutable x2) (immutable x3)))
(record-type-field-names
(record-type-descriptor
(make-triple 1 2 3))) (x1 x2 x3)
procedure: (record? obj)
returns: #t if obj is a record, otherwise #f
procedure: (record? obj rtd)
returns: #t if obj is a record of the given type, otherwise #f
If present, rtd must be a record-type descriptor.
procedure: (record-type-descriptor rec)
returns: the record-type descriptor of rec
rec must be a record. This procedure is intended for use in the definition of portable printers and debuggers. For records created with make-record-type, it may not be the same as the descriptor returned by make-record-type. See the comments about field accessibility and mutability under record-field-accessible? and record-field-mutable? above.
procedure: (record-reader type-name rtd)
returns: unspecified
record-reader registers rtd as the record-type descriptor to be used whenever the read procedure encounters a record named by type-name and printed in the default record syntax. type-name must be a string, and rtd must be a record-type descriptor.
(define-record marble (color quality))
(define m (make-marble 'blue 'high))
m #["marble" blue high]
(record-reader "marble" (record-type-descriptor m))
'#["marble" blue high] #["marble" blue high]
(marble-color '#["marble" blue high]) blue
The mark (#n=) and reference (#n#) syntaxes may be used within the record syntax, with the result of creating shared or cyclic structure as desired. All cycles must be resolvable, however, without mutation of an immutable record field. That is, any cycle must contain at least one pointer through a mutable field, whether it is a mutable record field or a mutable field of a built-in object type such as a pair or vector.
(define-record triple ((immutable x1) (mutable x2) (immutable x3)))
(record-reader "triple" (record-type-descriptor (make-triple 1 2 3)))
(let ((t '#["triple" #1=(1 2) (3 4) #1#]))
(eq? (triple-x1 t) (triple-x3 t))) #t
(let ((x '(#1=(1 2) . #["triple" #1# b c])))
(eq? (car x) (triple-x1 (cdr x)))) #t
(let ((t '#1=#["triple" a #1# c]))
(eq? t (triple-x2 t))) #t
(let ((t #["triple" #1# (3 4) #1=(1 2)]))
(eq? (triple-x1 t) (triple-x3 t))) #t
'#1=#["triple" #1# (3 4) #1#] error
This section describes an older mechanism, similar to records, that permits the creation of data structures with fixed ordered sets of named fields. Unlike record types, structure types are not unique types, but are instead implemented as vectors. Specifically, a structure is implemented as a vector whose length is one more than the number of fields and whose first element contains the symbolic name of the structure.
The representation of structures as vectors simplifies reading and printing of structures somewhat as well as extension of the structure definition facility. It does, however, have some drawbacks. One is that structures may be treated as ordinary vectors by mistake in situations where doing so is inappropriate. When dealing with both structures and vectors in a program, care must be taken to look for the more specific structure type before checking for the more generic vector type, e.g., in a series of cond clauses. A similar drawback is that structure instances are easily "forged," either intentionally or by accident. It is also impossible to control how structures are printed and read.
Structures are created via define-structure. Each structure definition defines a constructor procedure, a type predicate, an access procedure for each of its fields, and an assignment procedure for each of its fields. define-structure allows the programmer to control which fields are arguments to the generated constructor procedure and which fields are explicitly initialized by the constructor procedure.
define-structure is simple yet powerful enough for most applications, and it is easily extended to handle many applications for which it is not sufficient. The definition of define-structure given at the end of this section can serve as a starting point for more complicated variants.
syntax: (define-structure (name id1 ...) ((id2 val) ...))
returns: unspecified
A define-structure form is a definition and may appear anywhere and only where other definitions may appear.
define-structure defines a new data structure, name, and creates a set of procedures for creating and manipulating instances of the structure. The identifiers id1 ... and id2 ... name the fields of the data structure.
The following procedures are defined by define-structure:
The fields named by the identifiers id1 ... are initialized by the arguments to the constructor procedure. The fields named by the identifiers id2 ... are initialized explicitly to the values of the expressions val .... Each expression is evaluated within the scope of the identifiers id1 ... (bound to the corresponding field values) and any of the identifiers id2 ... (bound to the corresponding field values) appearing before it (as if within a let*).
To clarify, the constructor behaves as if defined as
(define make-name
(lambda (id1 ...)
(let* ([id2 val] ...)
body)))
where body builds the structure from the values of the identifiers id1 ... and id2 ....
If no fields other than those initialized by the arguments to the constructor procedure are needed, the second subexpression, ((id2 val) ...), may be omitted.
The following simple example demonstrates how pairs might be defined in Scheme if they did not already exist. Both fields are initialized by the arguments to the constructor procedure.
(define-structure (pare car cdr))
(define p (make-pare 'a 'b))
(pare? p) #t
(pair? p) #f
(pare? '(a . b)) #f
(pare-car p) a
(pare-cdr p) b
(set-pare-cdr! p (make-pare 'b 'c))
(pare-car (pare-cdr p)) b
(pare-cdr (pare-cdr p)) c
The following example defines a handy string data structure, called a stretch-string, that grows as needed. This example uses a field explicitly initialized to a value that depends on the value of the constructor argument fields.
(define-structure (stretch-string length fill)
([string (make-string length fill)]))
(define stretch-string-ref
(lambda (s i)
(let ([n (stretch-string-length s)])
(when (>= i n) (stretch-stretch-string! s (+ i 1) n))
(string-ref (stretch-string-string s) i))))
(define stretch-string-set!
(lambda (s i c)
(let ([n (stretch-string-length s)])
(when (>= i n) (stretch-stretch-string! s (+ i 1) n))
(string-set! (stretch-string-string s) i c))))
(define stretch-string-fill!
(lambda (s c)
(string-fill! (stretch-string-string s) c)
(set-stretch-string-fill! s c)))
(define stretch-stretch-string!
(lambda (s i n)
(set-stretch-string-length! s i)
(let ([str (stretch-string-string s)]
[fill (stretch-string-fill s)])
(let ([xtra (make-string (- i n) fill)])
(set-stretch-string-string! s
(string-append str xtra))))))
As often happens, most of the procedures defined automatically are used only to define more specialized procedures, in this case the procedures stretch-string-ref and stretch-string-set!. stretch-string-length and stretch-string-string are the only automatically defined procedures that are likely to be called directly in code that uses stretch strings.
(define ss (make-stretch-string 2 #\X))
(stretch-string-string ss) "XX"
(stretch-string-ref ss 3) #\X
(stretch-string-length ss) 4
(stretch-string-string ss) "XXXX"
(stretch-string-fill! ss #\@)
(stretch-string-string ss) "@@@@"
(stretch-string-ref ss 5) #\@
(stretch-string-string ss) "@@@@@@"
(stretch-string-set! ss 7 #\=)
(stretch-string-length ss) 8
(stretch-string-string ss) "@@@@@@@="
Section 8.4 of The Scheme Programming Language, Second Edition defines a simplified variant of define-structure as an example of the use of syntax-case. The definition given below implements the complete version.
define-structure expands into a series of definitions for names generated from the structure name and field names. The generated identifiers are created with datum->syntax-object to allow the identifiers to be visible where the define-structure form appears. Since a define-structure form expands into a begin containing definitions, it is itself a definition and can be used wherever definitions are valid.
(define-syntax define-structure
(lambda (x)
(define gen-id
(lambda (template-id . args)
(datum->syntax-object template-id
(string->symbol
(apply string-append
(map (lambda (x)
(if (string? x)
x
(symbol->string
(syntax-object->datum x))))
args))))))
(syntax-case x ()
((_ (name field1 ...))
(andmap identifier? (syntax (name field1 ...)))
(syntax (define-structure (name field1 ...) ())))
((_ (name field1 ...) ((field2 init) ...))
(andmap identifier? (syntax (name field1 ... field2 ...)))
(with-syntax
((constructor (gen-id (syntax name) "make-" (syntax name)))
(predicate (gen-id (syntax name) (syntax name) "?"))
((access ...)
(map (lambda (x) (gen-id x (syntax name) "-" x))
(syntax (field1 ... field2 ...))))
((assign ...)
(map (lambda (x) (gen-id x "set-" (syntax name) "-" x "!"))
(syntax (field1 ... field2 ...))))
(structure-length
(+ (length (syntax (field1 ... field2 ...))) 1))
((index ...)
(let f ((i 1) (ids (syntax (field1 ... field2 ...))))
(if (null? ids)
'()
(cons i (f (+ i 1) (cdr ids)))))))
(syntax (begin
(define constructor
(lambda (field1 ...)
(let* ((field2 init) ...)
(vector 'name field1 ... field2 ...))))
(define predicate
(lambda (x)
(and (vector? x)
(#3%fx= (vector-length x) structure-length)
(eq? (vector-ref x 0) 'name))))
(define access
(lambda (x)
(vector-ref x index)))
...
(define assign
(lambda (x update)
(vector-set! x index update)))
...)))))))
 |
Chez Scheme User's Guide © 1998 R. Kent Dybvig Cadence Research Systems http://www.scheme.com Illustrations © 1998 Jean-Pierre Hébert about this book |